
두번째 리뷰는 5장, 외국인 투수 스카우팅 최적화이다.
・ 주 최 : 데이콘, 서울대학교 통계연구소, 한국야구학회
・ 문 제 : 최종 스카우팅 선수 2명 선정과 그 과정에 대한 인사이트 보고서 제출
・ 평가 척도
- 전달력 : 코드 또는 시각화에 대한 설명이 얼마나 이해하기 쉬운지에 관한 가중치 0.5
- 논리성 : 어떤 선수를 스카우트 할 것인지에 대한 논리력 가중치 0.4
- 실용성 : 인사이트와 결과물이 실제 현업에서 쓸 수 있는 것인지에 관한 가중치 0.1
- 간결성 : 중요한 인사이트를 얼마나 간결하고 압축적으로 잘 표현했는지(동점 발생 시)
・ 기 간 : '19. 3. 26 ~ 5. 20
・ 참여 팀 : 80팀
이번 주제의 경우 평가척도가 다른 주제와 다소 다르게 예측값과 실제값의 일치도를 평가하는 것이 아닌, 인사이트 보고서를 제출, 평가하는 주제였다. 그런 점에서는 아마 다른 주제보다 현업과 더 유사하지 않을까 싶은 생각이 들었다.
소스코드는 역시나 데이콘 깃허브에 공개되어 있고, 데이터는 데이콘 홈페이지에서 받아 볼 수 있다.
・ 소스코드 : https://github.com/wikibook/dacon.git
・ 데이터 : https://dacon.io/competitions/official/68346/data
평소 야구는 물론 스포츠 자체에 별 관심을 두지 않아서 야구라는 도메인지식을 알아가는 데에 가장 많은 시간을 소모한 것 같다.
분석환경
import matplotlib
import numpy as np
import pandas as pd
import seaborn as sns
import statsmodels.api as sm
import os
print(matplotlib.__version__)
print(np.__version__)
print(pd.__version__)
print(sns.__version__)
print(sm.__version__)내 실행 결과는 아래와 같다. 실제 우승자분이 사용한 버전과 이것저것 다르지만, 진행상 크게 문제되는 점은 없다.
또한 디렉토리 변경을 위해 os 라이브러리도 추가로 불러줬다.
3.4.1
1.19.5
1.2.3
0.11.1
0.12.2
탐색적 데이터 분석(EDA)
전체 데이터분석에는 총 다섯개의 파일이 사용되는데 이는 크게 두 가지로 구분된다.
1. '11년~'18년 기간동안 KBO에서 활약한 외국인 투수 데이터
2. '19년에 MLB에서 활약한 신규 투수(스카우트 대상) 데이터
대략적으로 설명하면, 위 두 가지 자료 중 첫번째 자료를 가지고 MLB의 기록과 KBO의 기록에 대한 인사이트를 형성하고, 두 번째 데이터를 활용해서 실제 스카우트할 선수를 선별하는 방식이다.
여기서 또 다시 두 가지 종류로 자료가 나뉘어지는데, 첫번째 종류는 KBO와 MLB의 팬그래프 데이터이다. 먼저 이것을 불러와보자.
atKbo_11_18_KboRegSsn = pd.read_csv('kbo_yearly_foreigners_2011_2018.csv')
atKbo_11_18_MlbTot = pd.read_csv('fangraphs_foreigners_2011_2018.csv')
atKbo_19_MlbTot = pd.read_csv('fangraphs_foreigners_2019.csv')
print(atKbo_11_18_KboRegSsn.shape)
print(atKbo_11_18_MlbTot.shape)
print(atKbo_19_MlbTot.shape)
print(atKbo_11_18_KboRegSsn.columns)
print(atKbo_11_18_MlbTot.columns)
print(atKbo_19_MlbTot.columns)결과는 아래와 같다.
(105, 11)
(205, 19)
(41, 19)
Index(['pitcher_name', 'year', 'team', 'ERA', 'TBF', 'H', 'HR', 'BB', 'HBP',
'SO', 'year_born'],
dtype='object')
Index(['pitcher_name', 'year', 'ERA', 'WAR', 'TBF', 'H', 'HR', 'BB', 'HBP',
'SO', 'WHIP', 'BABIP', 'FIP', 'LD%', 'GB%', 'FB%', 'IFFB%', 'SwStr%',
'Swing%'],
dtype='object')
Index(['pitcher_name', 'year', 'ERA', 'WAR', 'TBF', 'H', 'HR', 'BB', 'HBP',
'SO', 'WHIP', 'BABIP', 'FIP', 'LD%', 'GB%', 'FB%', 'IFFB%', 'SwStr%',
'Swing%'],
dtype='object')역시나 shape를 통해 전반적인 데이터의 형태를 알 수 있고, columns로 데이터의 내용을 알 수 있다.
- 각 컬럼별 상세내용
pitcher_name : 투수 이름 / year : 연도 / team : 소속팀 / ERA :평균자책점 / WAR : 대체선수 대비 승리 기여도
TBF : 상대한 타자 수 / H : 피안타 수 / HR : 피홈런 수 / BB : 피볼넷 수 / HBP : 피사구 수 / SO : 삼진 수
year_born : 생년월일 / WHIP : 이닝당 출루 허용률 / BABIP : 인플레이 타구 안타 비율 / FIP : 수비 무관 자책점
LD% : 라인드라이브 비율 / GB% : 땅볼 비율 / FB% : 플라이볼 비율 / IFFB%플라이볼 중 인필드 플라이볼 비율
SwStr% : 헛스윙 비율 / Swing% : 스윙 비율
평소에 야구는 커녕 스포츠 자체를 별로 안좋아하니 참,, 낯설다. 그냥 처음 본 느낌으로는 굳이 이런것까지..? 싶긴 한데, 뭐 다들 필요하니까 기록 해 놓은 거겠지...
atKbo_11_18_KboRegSsn[['ERA', 'TBF']].hist()
print(atKbo_11_18_KboRegSsn[['ERA', 'TBF']].describe())우승자분은 주요 지표로 ERA(평균자책점)와 TBF(상대한 타자수)를 선정했다. 그리고 이에 대해 히스토그램과 describe() 함수를 통해 대략적인 분포를 확인 해 보면 다음과 같다.
먼저 KBO부터 살펴보자.
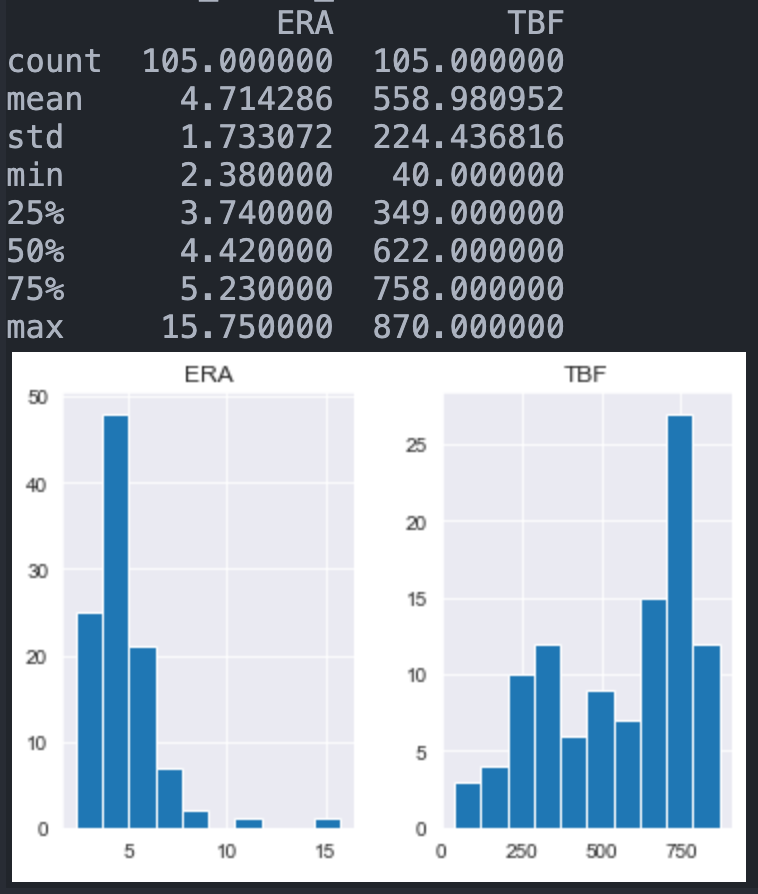
ERA는 평균이 약 4.7이고 대부분의 값이 3~5 사이에 분포되어있으며, TBF의 경우에는 평균이 약 559이고 대부분이 350~750정도에 분포해 있는 것을 볼 수 있다.
다음은 MLB에서의 기록이다.
atKbo_11_18_MlbTot[['ERA', 'TBF']].hist()
print(atKbo_11_18_MlbTot[['ERA', 'TBF']].describe())
MLB에서는 ERA의 평균값이 약 5.7, 대부분의 값이 4~6.75 사이에 분포되어있다. 반면에 TBF의 경우 평균값은 193이고 대부분이 50~250정도에 분포하는 것을 볼 수 있다. 이를 통해 국내에서 활동하는 외국인 투수들은 대부분 MLB에서 투구 기회가 적었다고 볼 수 있고, 이는 아마도 KBO에서 활동하는 대부분의 외국인 투수가 MLB에서는 선발투수로 활동하지 못했다는 것으로 볼 수 있다.
위에서 살펴본 자료에서, ERA는 투수를 평가하는 지표로 주로 활용된다고 한다. 따라서 MLB에서 ERA가 낮을수록, KBO에서도 ERA가 낮을 것이라는 가설을 세우고, 이것이 맞다면 새로운 투수를 스카우트 할 때 ERA를 그 판단 지표로 활용 할 수 있다는 주장을 할 수 있을 것이다.
m_mean = (atKbo_11_18_MlbTot.groupby('pitcher_name')['ERA'].
mean().
reset_index().
rename(columns = {'ERA':"MLB_mean"}))
k_mean = (atKbo_11_18_KboRegSsn.groupby('pitcher_name')['ERA'].
mean().
reset_index().
rename(columns = {'ERA':'KBO_mean'}))
df = pd.merge(m_mean, k_mean, how = 'inner', on = 'pitcher_name')
df.head()여기서 나중에 활용 할 수 있는 신기한 코딩 방법을 배웠다.
보통 코드가 지나치게 길어질 때에는 \(역슬래시)를 이용해서 코드를 분할 했는데, 여기서는 코드를 괄호로 묶어주고 각 함수 단위로 코드를 잘라서 표시했다. 이를 통해 코드를 읽기로 쓰기에 훨씬 편했다.
먼저 MLB와 KBO의 자료에 대해서 각각 투수명을 기준으로 자료들을 묶어 준 후, ERA 컬럼에 대해서만 각각 m_mean과 k_mean에 저장해준다. 이 때 reset_index를 통해 투수이름을 컬럼으로 꺼내준 뒤, ERA를 각각 MLB_mean과 KBO_mean으로 변경해준다.
이후 두 변수 m_mean과 k_mean을 merge함수로 병합하는데, 이때에는 기준을 투수명으로 하고, how = 'inner'로 지정하여 두 데이터프레임에 있는 자료 중 공통된 자료만을 저장한다.
즉, MLB와 KBO 모두에서 활동 기록이 있어, 비교가 가능한 선수들의 명단만 종합하는 것이다. 이는 m_mean의 shape는 (60, 2), k_mean의 shape는 (62, 2)인데 df.shape의 결과는 (59, 3)이라는 점을 통해 알 수 있다.
이렇게 만들어진 결과물 df를 산점도로 표현하여, 과연 두 변수 사이에 어떠한 관계가 있을지 눈으로 확인 해 보자.
df.plot(kind = 'scatter', x = 'MLB_mean', y = 'KBO_mean')
print(df.corr())
음, 그려놓고 보니 큰 상관관계는 없어보인다. 실제로 상관계수 또한 0.1077로 거의 상관관계가 없다는 것을 알 수 있다. 우승자분은 아마도 야구라는 스포츠에서 자책점은 투수의 기량 외에도 다른 수많은 요소들이 작용하기에 이런 결과가 나온 것이라고 추측했다.
다음으로는 statcast에 기록된 자료들을 살펴보는데, 야구를 전혀 모르는 내가 보기에 아마 이 자료는 야구에 대한 지표라기보다는 정말 투수의 능력 자체를 기록하고자 하는 지표인 것으로 보인다. 우선 코드를 보자.
atKbo_11_18_StatCast = pd.read_csv('baseball_savant_foreigners_2011_2018.csv')
atKbo_19_StatCast = pd.read_csv('baseball_savant_foreigners_2019.csv')
print(atKbo_11_18_StatCast.shape)
print(atKbo_19_StatCast.shape)
print(atKbo_19_StatCast.columns)
print(atKbo_19_StatCast.columns)실행 결과는 아래와 같다.
(135753, 24)
(21903, 24)
Index(['game_date', 'release_speed', 'batter', 'pitcher', 'events',
'description', 'zone', 'stand', 'p_throws', 'bb_type', 'balls',
'strikes', 'pfx_x', 'pfx_z', 'plate_x', 'plate_z', 'ax', 'ay', 'az',
'launch_speed', 'launch_angle', 'release_spin_rate', 'pitch_name',
'pitcher_name'],
dtype='object')
Index(['game_date', 'release_speed', 'batter', 'pitcher', 'events',
'description', 'zone', 'stand', 'p_throws', 'bb_type', 'balls',
'strikes', 'pfx_x', 'pfx_z', 'plate_x', 'plate_z', 'ax', 'ay', 'az',
'launch_speed', 'launch_angle', 'release_spin_rate', 'pitch_name',
'pitcher_name'],
dtype='object')첫인상만 보더라도 팬그래프 자료에 비해 비교도 안 될 만큼 엄청나게 많은 자료가 기록되어있음을 알 수 있다. 한 경기에서도 수 백개의 공이 던져지는데 그것을 전부 기록하다보니 자료의 양이 많아진 것으로 보인다. 이 자료의 각 컬럼들이 표현하는 내용은 아래와 같다.
- 각 컬럼별 상세내용
game_date : 경기 일자 / release_speed : 구속 / batter : 타자 / pitcher : 투수 / events : 타석의 결과 / description : 공의 결과
zone : 공이 홈플레이트를 지날 때 의 위치 / stand : 타자의 손잡이 / p_throws : 투수의 손잡이 / bb_type : 타구의 유형
balls : 직전 볼카운트 중 볼 수 / strikes : 직전 볼카운트 중 스트라이크 수 / pfx_x / pfx_z : : 공의 수평, 수직 움직임
plate_x / plate_z : 공이 홈플레이트를 지날 때의 수평, 수직 위치(피트) / ax / ay / az : 공의 가속도 x, y, z 성분
launch_speed : 타구의 속도 / launch_angle : 타구의 발사각도 / release_spin_rate : 투수가 던진 공의 회전율
pitch_name : 구종 / pitcher_name : 투수 이름
우승자분은 이 자료들 중에서 events, description, pitcher_name 세 가지에 대해 탐색을 진행했다.
atKbo_11_18_StatCast[['events', 'description', 'pitch_name']]
atKbo_11_18_StatCast[['events', 'description', 'pitch_name']].info()
atKbo_11_18_StatCast[['events', 'description', 'pitch_name']].describe()


위 상세내용에 작성했듯, events에는 해당 타석의 결과, description에는 해당 투구의 결과, pitch_name에는 투구의 종류가 기록되어있으며, 타석의 결과에는 타자별로 1개의 기록만 되어있으므로 대부분이 NaN임을 알 수 있다.
또한 info를 찍어봤을 때 세 컬럼 모두 object형태인 것을 알 수 있고, 이때문에 describe를 통해 많은 정보를 얻을 수는 없지만 각각 26, 15, 14개의 다른 값들이 반복되고 있다는 것을 알 수 있다.
그러면 각 컬럼별로, 어떤 값들이 주로 기록되어있는지를 살펴보자.
(atKbo_11_18_StatCast['events'].
value_counts().
sort_values(ascending = True).
plot(kind = 'barh', figsize = (8, 8)))여기서도 우승자분은 괄호와 엔터를 통해 깔끔하고 보기 좋은 코드를 사용했다.

그래프를 그릴 때에도 참 여러가지 방법이 있는데, 적절하게 잘 활용하시는 것 같다. 이렇게 컬럼 명이 길어지는 경우에는 확실히 세로형 막대그래프보다는 barh를 활용한 가로형 막대그래프가 훨씬 보기도 좋고, 깔끔하다.
events 컬럼에서는 field_out이 약 15000개로 가장 많은 빈도를 차지했고, 그 뒤로 single과 strikeout이 가장 많은 빈도수를 보였다.
(atKbo_11_18_StatCast['description'].
value_counts().
sort_values(ascending = True).
plot(kind = 'barh', figsize = (8, 8)))다음으로 description 컬럼에 대해서도 동일하게 실행해준다.

여기서는 ball 이 가장 높은 비율을 차지했다. 사실 난 야구에 이렇게 많은 결과가 있을줄은 몰랐다. 그냥 볼, 스트라이크, 파울정도 있을 줄 알았는데,,
(atKbo_11_18_StatCast['pitch_name'].
value_counts().
sort_values(ascending = True).
plot(kind = 'barh', figsize = (8, 8)))동일하게 구종에 대해서도 보면,

4심 패스트볼 비중이 가장 큰 것으로 나타난다. 아무래도 가장 무난해서 그런가 싶다.
우선은 간단하게 EDA부분만 리뷰하고, 나중에 전처리와 모델 구축, 향상방안 등에 대해서도 리뷰를 하겠다. 꾸준히 해야할텐데, 자꾸 튀는 것 같아서 걱정이다.