
아,, 쓰기전부터 피곤하다. 사진이 너무 많다.. 공부용으로 급 기록하려다보니 뭔가 좀 많이 조잡해지는것같다.
우선 버추얼박스부터 깔아준다.

버추얼박스가 설치되면 우분투 이미지 파일을 찾아준다.
최신버전은 아니지만 안정적이고 호환성이 좋은 ubuntu 18.04를 찾아서 설치해주자
맨 윗 게시물을 눌러보면,

요런 창이 뜨는데, 무턱대고 누를 게 아니라 아래로 좀 내려준다.

내리다 보면 이렇게 보이는데, 여기에 표시한 서버용을 설치해준다.

지금 시점에서 나는 이미 설치를 했으므로 가상머신이 이미 있는데, 처음엔 새로 만들기를 클릭해서 세팅준비를 해준다.
누르면 아래와 같은 창이 열린다.

나는 당장 이름이 겹치기때문에 0을 추가했다. 뭐 사실 이름과 경로는 본인 마음이고, 종류와 버전만 잘 맞춰준다.

난 처음 만들때 혹시나 해서 4기가로 했었는데, 그냥 2기가만 해도 충분 할 것 같다. 모자라면 지우고 다시하지 뭐..

가상디스크 만들어서 해주고,
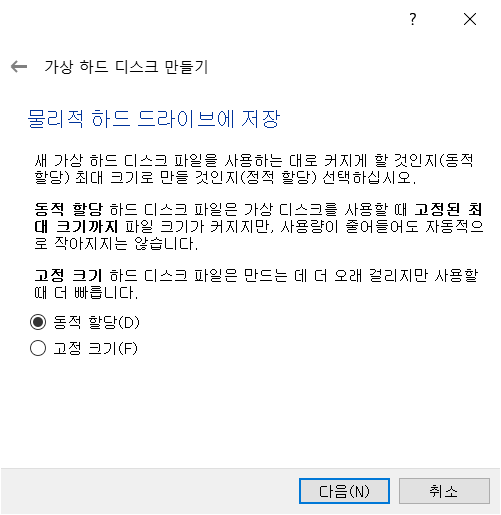
하드나 SSD 용량으로 고생 안하려면 동적할당이 확실히 나을것같다.

이렇게 기본적인 세팅만 하면 우선 가상머신은 생성된다. 다만 이렇게 껍데기만 만들어진 머신에 이전에 다운받은
우분투 이미지파일을 일종의 시동디스크로 활용해서 설치 해 주면 된다.

요렇게. 경로는 아까 설치한 그 파일 찾아보면 된다.

이렇게 주루루룩 부팅이 되다가,

언어를 선택하라고 하는데, 종종 여기서 글시가 깨지더라. 어차피 한글 없으니까 뭔가 화면 이상하다 싶으면 그냥 엔터를 눌러준다.

네트워크 설정도 안되어 있어서 눌러도 어차피 안된다. 업데이트 없이 그냥 진행 해준다.

뭔지 잘 모르겠다. 하지만 뭔가 설치할때 어지간한 짬이 아니면 커스텀은 하지 말자는건 본능적으로 알고있다.
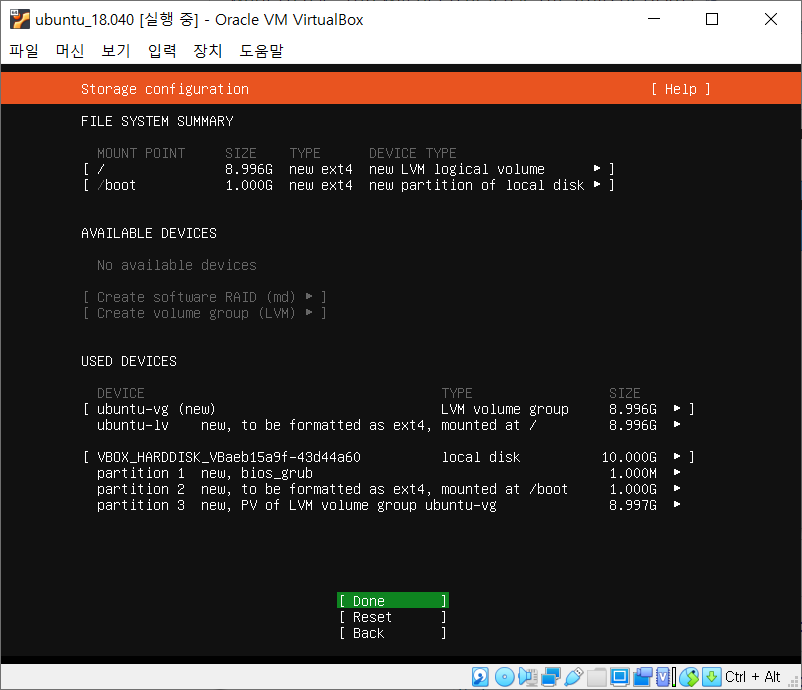
뭐 그 뒤로 자질구레한것들 나오는데, 그냥 다 Done 해준다.

뭔가 위험해보이지만 당장 중요하지 않다. 그냥 진행한다.
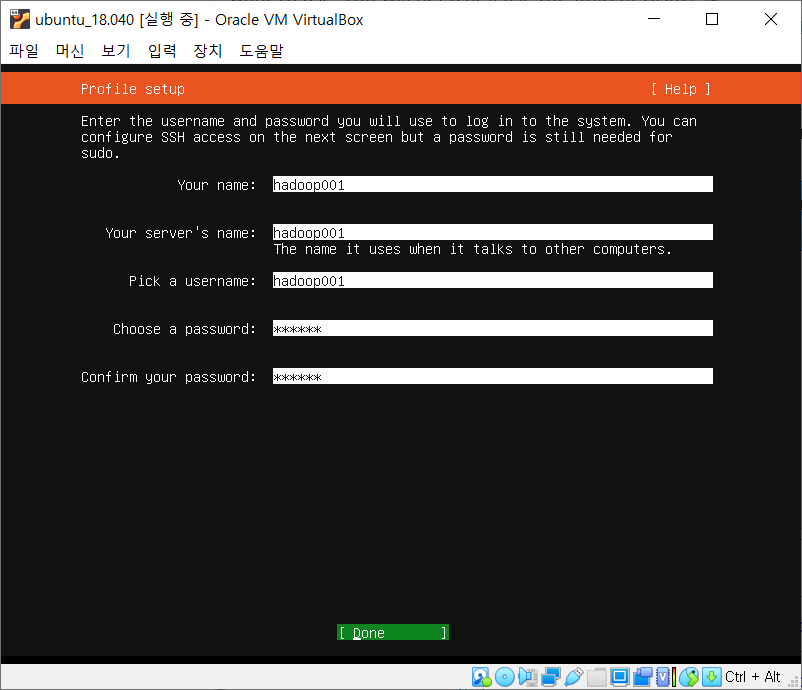
계정 이름과 비밀번호를 설정해준다. 정말 꼭 비밀번호에 유의할것.
설정이 끝나고 설치가 쭉 이어진다. 여기서 한 20분 정도 걸린 것 같다.

리부트 버튼이 생기면 재부팅해준다.

뭔가 실패한것같지만 우선 중요하지 않다. 어차피 이건 지워버릴 머신이니까..

재부팅이 완료되면 계정과 비밀번호를 입력하여 실행. 비밀번호 입력은 원래 공백이니 신경쓰지말고 계속 입력해준다. 아직 솔직히 적응이 덜됐다.
이제 처음 우분투에 로그인하면 이렇다. 휑하다. 아직은 GUI가 그립다.

일단 sudo -i 를 입력해서 root 권한을 받아준다.

그리고 이제 본격적으로 프로그램들을 설치 해 줄 준비를 한다.
우리의 목표는 Hadoop 설치인데, 그러기 위해서는 JAVA도 같이 설치를 해 주어야 한다. 고로 우리는 총 두 가지 파일을 우선 설치해야 한다.
1. Hadoop
2. jdk
일단 하둡을 찾아보자

중앙에 있는 다운로드를 눌러준다.
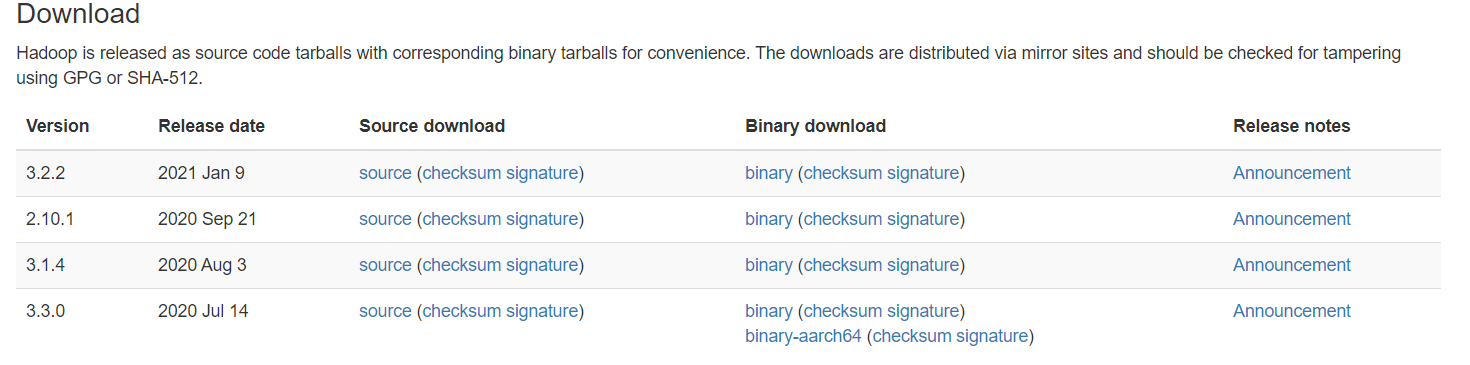
우리가 받을 버전은 3.2.2로 맨 위에 있다. 그중에서 binary를 눌러준다.

여기에 나온 주소를 복사해서 wget으로 받으면 간단하다.
$ wget https://mirror.navercorp.com/apache/hadoop/common/hadoop-3.2.2/hadoop-3.2.2.tar.gz아, 그런데 가상머신에서는 복붙이 안된다. 그냥 손으로 쳐서 설치도 해봤는데 뭔가 다른 파일이 설치가 되더라.
그래서 이번엔 푸티(Putty)를 깔아준다.

들어가서 우리 버전에 맞는 푸티를 받아준다.
나는 64bit x86을 받았다.

실행파일이므로 바로 켜준다. 그러면 아래와 같은 창이 뜬다.
접속 방법은, 우분투 가상머신에서
$ ip address를 입력해주면

왼쪽 그림처럼 여러가지 정보를 표시해준다. 그 중에 우리가 필요한 정보는 밑줄친 빨간색 한 줄 뿐이다.
이곳과 관련해서는 다른 분들께서 이미 잘 정리 해 주신 게 있어서 넘어가자
참고 : 죄진 님 티스토리
아, 나같은 경우에는 네트워크 설정에도 문제가 있었는데, 그 부분은 여기를 참고 바란다.

보안 관련 경고문구가 뜨는데, 일단 Accept해준다.

자 이렇게 푸티로 우분투 창이 열렸다. 아까 했던 것 처럼 sudo -i로 루트 권한을 받아서 루트 디렉토리 밑에 dev 디렉토리를 만들어 준다. 나는 이미 만들어져 있어서 생략했다.
cd dev/ 해서 dev디렉토리로 들어가준다.
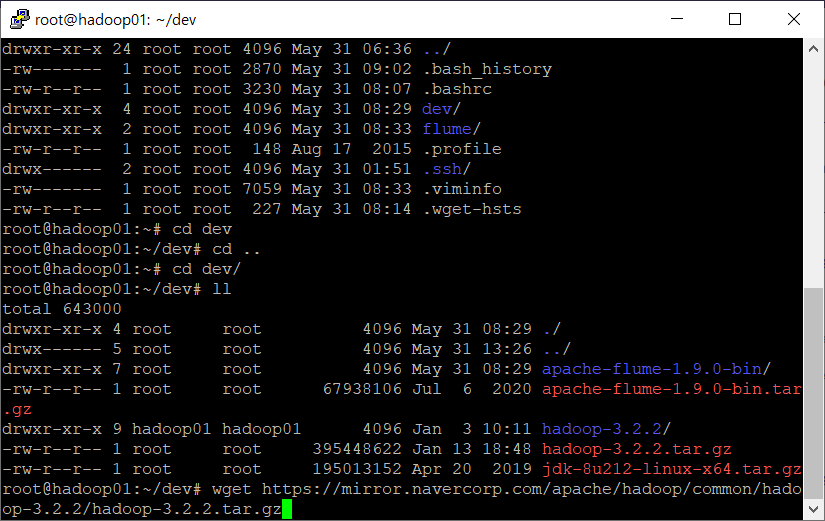
dev 안에서, 아까 하려고 했던 하둡 압축파일 설치를 해준다.
이번엔 shift + insert키로 붙여넣기가 가능하다.
$ wget https://mirror.navercorp.com/apache/hadoop/common/hadoop-3.2.2/hadoop-3.2.2.tar.gz
이어서 jdk파일도 받아줘야 하는데, 이부분이 좀 난감했다.
오라클 홈페이지 주소로는 wget이 안되고, 깃허브에도 뭔가 이상한 파일들이 돌아다니길래 찾아본 결과는
$ wget https://github.com/frekele/oracle-java/releases/download/8u212-b10/jdk-8u212-linux-x64.tar.gz혹은
$ sudo apt-get install openjdk-8-jre를 사용 해 주면 된다.
둘 다 가능한 방법인데 경로잡기는 위가 좀 더 편한 것 같더라.
아니면 윈도우에서 파일을 어떻게든 받은 후 winSCP를 이용해 가상머신에 넣어주는 방법도 있다.

이것도 물론 검색하면 나온다. 구글 없으면 어떻게 살지?

간단하니 쭈욱 손 가는대로 설치해준다.

설치가 완료되면 실행해서 푸티와 같은 방법으로 실행 해 준다. 다만, 사용자 이름과 비밀번호를 같이 넣어줘야 한다.
추가적으로, SCP의 경우에는 권한 문제로 파일을 hadoop01(이전에 만든 사용자) 폴더까지밖에 넣을 수 없다. 그러므로 dev 디렉토리에서 별도로 cp를 써서 카피해와야하는 번거로움이 있다.
고로 어지간하면 그냥 위에 있는 방법을 쓰자.

여차저차 dev 디렉토리에 hadoop과 jdk를 넣어줬다면, 둘다 그 자리에서 압축을 풀어준다.
압축 해제에는 tar xvf [파일명]을 사용한다.
이후 압축해제된 각 디렉토리에 들어가서 pwd로 경로를 따준다.
그리고 .bashrc를 보러가자. 다시 root 로 이동한다.

솔직히 .bashrc 다루기 번거롭다.. 뭐 하나 잘못바꾸면 또 귀찮아지니까. 일단 열어주고 i 를 눌러주면 수정 모드가 된다. 그 뒤 맨 아래로 이동한다.

그 후 위와 같이 작성 해 준다. 음 하둡을 저렇게 이상하게 두지 말고 정리할껄 그랬나 싶지만,, 이미 스샷을 다 찍은 관계로 다음에 정리하자.
물론 방법이 달라서 설치 위치가 다른 경우에는 각 bin 디렉토리를 찾아서 그 이전 경로까지 입력 해 주면 된다.(자바의 경우 jre이전까지)
아, 추가로 여기서 등호 앞뒤로 공백문자가 포함되면 문법상 틀린것으로 적용된다. 꼭 띄어쓰기 없이 작성하도록 하자.
그리고 esc를 누른 후 :wq를 입력해서 나와준다.
여기서 종종 읽기전용이라고 협박하는 경우가 있는데, 그냥 :wq!로 강제 저장 해 준 뒤, 잡다한 .swp, swo파일 등등을 지워주면 해결된다.
무사히 나왔다면 source .bashrc를 통해 변경사항을 적용 해 준다.
만약 엄한 걸 건드렸거나 해서 ll, cd 등 모든 명령어가 먹통이 된다면,, 내 티스토리 etc 게시판에 해결법이 있으니 참고 바란다.
아,, 귀찮으실테니 그냥 여기다 적겠다.
$ export PATH=%PATH:/bin:/usr/local/bin:/usr/bin이걸 입력 해 주면 일단 다시 명령어가 작동 할 것이다. 이후 다시 배쉬를 수정 해 주자.
뭔가 뒤로 갈수록 스샷이 줄어드는건,, 음,, 다음으로 넘어가자
아무튼, 경로가 올바르게 적용되었다면 어디서든 hadoop, java를 입력했을 때 아래와 같은 모습을 볼 수 있다.


와,, 플럼까지 포스팅 하려고 했는데 왜이리 길어지나,, 빨리 끝내도록 하자.

역시 검색하면 나온다.

왼쪽 Download 클릭 후 맨 위의 binary tar.gz를 클릭한다.
그러면 이런 아까와 비슷한 창이 나온다.

푸티가 있는 우리는 이제 복붙이 가능하다. 역시나 wget으로 받아준다.
$ wget https://mirror.navercorp.com/apache/flume/1.9.0/apache-flume-1.9.0-bin.tar.gz자, 다 받았으면 아까와 같이 압축을 풀어준다.

tar xvf는 왜인지 자꾸 손에 익지 않는다. 자주 써버릇 하자. 역시나 나는 이미 압축이 풀려있다.

이후 root로 이동해서 이번에는 mkdir flume으로 flume이라는 디렉토리를 만들어준다.

그리고 그 디렉토리로 들어가서 flume.conf라는 빈 파일을 우선 만들어준다.
vi는 열때도 쓰지만, 없는 파일명을 쓰면 새 파일을 만들어준다. 그래서 제목에 오타가 나는지 꼭 확인해야 한다.
그 후 다시 플럼 공식문서로 가준다.

이번엔 Download가 아닌 Documentation으로 가서 User Guide를 열어준다.
그리고 조금만 내려가면 아래와 같은 코드가 보인다.

당장 가기 귀찮다면 아래의 코드를 써주도록 하자. 똑같다.
공식문서에 들어갔다면 이따 또 써야하므로 닫지 말자.
# example.conf: A single-node Flume configuration
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1이 내용을 그대로 복사해서 방금 만든 flume.conf 내부에 붙여넣어준다.
그러면 이렇게 된다.

esc 와 :wq를 통해 저장하고 나와준다.
이후 다시 dev 디렉토리로 이동하여 방금 압축을 풀었던 flume의 디렉토리로 들어가준다.

여기서 다시 한 번 공식문서로 이동해서 방금 복사한 코드의 아래쪽을 보면 아래와 같은 코드가 있다.

$ bin/flume-ng agent --conf conf --conf-file example.conf --name a1 -Dflume.root.logger=INFO,console이 코드는 그냥 복붙은 아니고, 손을 좀 봐줘야 한다. 중간쯤에 보면 example.conf라고 되어있는데, 이부분에 우리가 만든 flume.conf를 넣어줘야 한다. 그 방법은
1. 절대주소로 때려넣기
$ bin/flume-ng agent --conf conf --conf-file /root/flume/flume.conf --name a1 -Dflume.root.logger=INFO,console2. 상대주소로 넣기
$ bin/flume-ng agent --conf conf --conf-file ../../flume/flume.conf --name a1 -Dflume.root.logger=INFO,console사실 뭘 하던 똑같다.
아니면 본인이 설치하고 파일을 만들어준 경로를 넣어주면 된다.
난 1번 방법으로 넣어줬다.

그러면 아래와 같은 결과가 나온다.

요렇게 44444가 보인다면 연결된것이다.
확인하기 위해 푸티를 하나 더 열어준다. 그냥 한번 더 열면 열린다.

위의 방법과 동일하게 열어준다. 푸티 말고 우분투 가상머신에 아까 표시한 주소가 있을테니 그쪽을 보는 게 편할 것 같다.

그렇게 무사히 푸티 창 하나를 더 열어준 뒤, 아래와 같이 입력해준다.
$ telnet localhost 44444그러면 아래처럼 Connected to localhost라는 멘트가 나온다. 확인하고싶다면 Hello world든 뭐든 입력하고 엔터를 쳐보자. OK라고 답이 온다면 연결된 것이다.

OK라는 답과 동시에 기존에 연결할때 썼던 푸티 창에서는 요렇게 이벤트가 표시된다. 참고바람.

이렇게 진짜. 후루룩 야매로 작성한 하둡 설치방법이 끝났다.
가면 갈수록 사진의 빈도가 줄어들고 자꾸 말로 떼우고, 뭔가 빠진 것도 있을 것 같다.
아무래도 블로그 포스팅은 커녕 글을 써 본 적도 없어서 더욱 뭔가 많이 미숙한것같다.
발전하려면 계속 써 보는 수 밖에 없겠지.
이걸 볼 미래의 나에게, 꼭 참고가 됐으면 좋겠구나. 힘내고..